V oblasti lokálního běhu umělé inteligence (AI) v roce 2026 platí jedno neúprosné pravidlo: VRAM je král. Zatímco u běžných herních PC řešíte hrubý výkon, pro efektivní AI inferenci tvoří kapacita grafické paměti celých 90 % úspěchu. Pokud se váš model nevejde do paměti GPU, zažijete drastický propad rychlosti z plynulých sekundu na nepoužitelně pomalou záležitost.
Tento průvodce vám ukáže, jak postavit stroj, který v roce 2026 utáhne i ty nejnáročnější modely bez nutnosti platit tisíce dolarů měsíčně za cloudové služby.
💡 Klíčové poznatky
- VRAM je víc než výkon: Kapacita paměti je důležitější než počet jader. Pro 70B modely potřebujete minimálně 40 GB VRAM.
- NVIDIA 3090 je stále vítězem: Bazarová RTX 3090 (24 GB) nabízí nejlepší poměr cena/výkon díky podpoře NVLink.
- Apple Silicon dominuje v paměti: Díky až 512 GB sjednocené paměti dokáže Mac Studio s Apple Siliconem běžet velké LLM v rámci jedné stanice, zatímco na PC straně se pro podobnou kapacitu často používají multi‑GPU sestavy s NVLinkem.
- Linux pomůže: Windows si rezervují až 2 GB VRAM pro systém, což může být rozdíl mezi funkčním modelem a pádem aplikace.
⚡Rychlý výběr
RTX 5060 Ti (16GB)

Ideální vstupní brána do světa lokálních AI.
- VRAM: 16 GB GDDR7
- AI akcelerátor: 5. generace
- Výhoda: Solidní poměr cena/výkon
Laptop RTX 5080

Pracovní stanice pro vývojáře. 16GB VRAM dovoluje spouštět těžší modely lokálně i při multitaskingu.
- VRAM: 16 GB GDDR7
- RAM: 32 GB
- Procesor: Intel Core 7 240H
MacBook Pro M4 Max

Specialista na velké AI modely. Díky unifikované paměti až 128 GB zvládne projekty, na kterých běžné notebooky často končí kvůli nedostatku paměti.
- RAM: 36 – 128 GB
- Čip: Apple M4 Max
- Výdrž: Až 24 hodin
Proč na kapacitě paměti záleží víc než na čipu
Představte si VRAM jako motor vašeho AI stroje. Čím větší část modelu se vejde přímo do této paměti, tím rozumnější rychlostí poběží. Jakmile narazíte na limit VRAM, knihovny začnou data ‚swapovat‘ do operační paměti a i nejvýkonnější procesor se stává brzdou, protože propustnost mezi GPU a RAM je jen zlomkem toho, co AI výpočty potřebují.
Tento problém se navíc stupňuje s délkou kontextu. Čím delší konverzaci s AI vedete, tím více paměti zabírá takzvaná KV Cache. U dlouhých dokumentů tak můžete narazit na limit dříve, než stačíte položit druhou otázku.
To nás přivádí k zásadnímu rozhodnutí: postavit klasické PC s více kartami, nebo vsadit na sjednocenou architekturu od Apple?
Srovnání hardware: Která cesta je pro vás?
| Komponenta / Systém | Kapacita VRAM | Odhadovaná cena (2026) | Vhodné pro modely |
| NVIDIA RTX 5060 Ti | 16 GB | ~16 000 Kč | Mid-range (13B-20B) |
| RTX 3090 (Bazar) | 24 GB | ~20 000 Kč | Nadšence (komfort pro 16-20B, možnost multi‑GPU) |
| NVIDIA RTX 5090 | 32 GB | ~85 000 Kč | High-end (30B+ s vysokou rychlostí) |
| Mac Studio M3 Ultra | 512 GB | ~300 000 Kč | Gigantické modely (DeepSeek R1) |
Architektonické pasti: PCIe linky a propustnost
Pokud se rozhodnete jít cestou více grafických karet, narazíte na problém, který většina běžných prodejců PC ignoruje: rozdělení PCIe linek. Pro seriózní AI práci je důležité, aby základní deska uměla alespoň konfiguraci x8/x8 přímo z procesoru, jinak jedna z karet běží přes výrazně pomalejší připojení a stává se úzkým hrdlem celé sestavy.
Kvantizace: Jak nacpat obra do krabice od bot
Nebylo by fér tvrdit, že k běhu velkých modelů potřebujete jen hrubou sílu. Softwarová kouzla zvaná kvantizace umožňují spouštět modely v redukované přesnosti (např. 4-bit) při zachování téměř identické inteligence. Podle aktuálních testů snižuje 4-bitová kvantizace nároky na paměť zhruba na čtvrtinu.
Zatímco na NVIDIA GPU se nejčastěji používají kvantizované formáty jako GPTQ nebo extrémně rychlé EXL2, uživatelé Maců a CPU zpravidla sázejí na formát GGUF z ekosystému llama.cpp. GGUF je navržený pro efektivní běh na CPU, Apple Silicon i GPU a díky podpoře offloadu a mapování souborů umožňuje rozumně plynulý běh i tehdy, když model částečně přetéká mimo VRAM do RAM nebo na disk.
Nároky modelů v 4-bitové kvantizaci (2026)
- 7B parametrů: cca 6 GB VRAM (stačí i levnější notebook).
- 30B parametrů: 16–20 GB VRAM (vyžaduje např RTX 5060 Ti 16GB nebo 3090).
- 70B parametrů: 35–40+ GB VRAM (zde už potřebujete dvě RTX 3090/4090 případně kombinaci VRAM + offload do RAM).
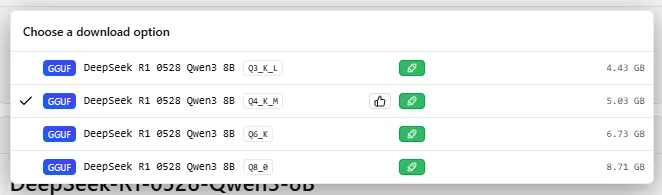
- 671B (DeepSeek R1): ~335 GB VRAM (doména Mac Studio nebo enterprise clusterů).
Operační systém: Proč Windows pálí vaše peníze
Nenechte se zmást pohodlím Windows 11. Pro seriózní AI práci je tento systém nevhodný, protože si pro své grafické rozhraní rezervuje až 2 GB drahocenné VRAM. V momentě, kdy bojujete o každý megabajt, abyste spustili model s větším kontextem.
Přechod na Linux (například Ubuntu 24.04) uvolňuje tuto paměť přímo pro vaše potřeby. Navíc instalace ovladačů NVIDIA (CUDA) a nástrojů jako Docker je na Linuxu plynulá a stabilní. Pokud se na terminál necítíte, moderní nástroje jako Ollama nebo LM Studio dnes umožňují zprovoznění lokální AI „jedním“ kliknutím.
Často kladené otázky (FAQ)
Nestačí mi Cloud (ChatGPT/Claude)?
Cloud má měsíční poplatky, limity zpráv, cenzuru a nulové soukromí. Lokální AI běží offline, bez limitů a vaše citlivá data nikdy neopustí vaši síť.
Nahradí NPU v nových procesorech grafické karty?
V roce 2026 jsou NPU (Neural Processing Units) v procesorech Intel a AMD skvělé pro úsporu baterie v noteboocích, ale pro vážnou práci s velkými modely stále postrádají potřebnou paměťovou propustnost dedikovaných GPU.
Je nastavení více grafických karet složité?
Díky moderním wrapperům jako Ollama je rozdělení modelu mezi více karet (GPU splitting) automatické. Nemusíte nic programovat, software si sám zjistí kapacitu vašich karet.